年初早々発生したSlackの大規模障害は「仕事始め」が原因だった

2021年の年初に発生したSlackの大規模障害について、Slackが障害の原因をまとめたレポートを公開しました。年末年始の長期休暇明けの「仕事始め」が、障害の根本的な原因だったようです。
Slack’s Outage on January 4th 2021 - Slack Engineering
https://slack.engineering/slacks-outage-on-january-4th-2021/

太平洋標準時の2021年1月4日、Slackに大規模なアクセス障害が発生。この障害は1月4日午前6時ごろから始まり、午前7時から午前8時30分頃まで、Slackにアクセスできない状況が続きました。
Status Site
https://status.slack.com/2021-01/9ecc1bc75347b6d1
2021年1月4日、Slackのインフラチームはサービスのエラー率上昇や監視システムの異常を観測し、調査を開始。内部のコンソールやステータス画面、ロギング基盤、メトリクス出力基盤などは正常に動作していましたが、Slack上で送信に失敗しているメッセージの割合が少し多い状態でした。原因は上流のネットワーク障害であると判明したため、SlackはクラウドプロバイダーのAWSに報告したとのこと。この時点では、それほど大きな障害には至っていませんでした。
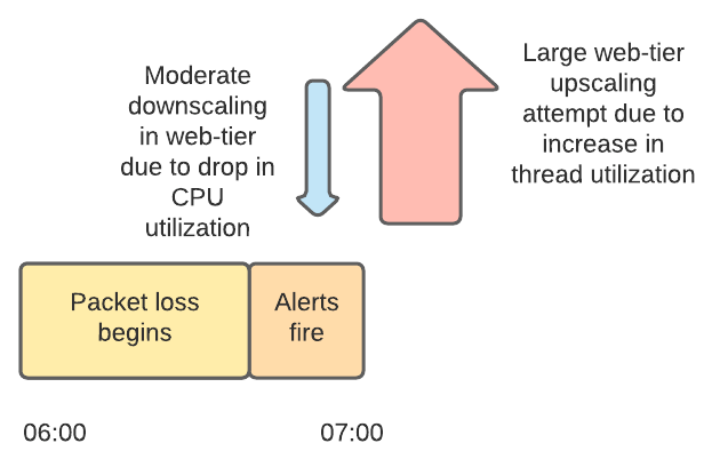
しかし、太平洋標準時における午前7時の「ミニピーク」時、Slackのウェブ層はアクセスを処理しきれずパケットロスし始め、最終的にはサービス全体がダウン。この「ミニピーク」はSlackに特徴的なアクセスパターンで、定期実行されるメッセージ送信により「毎時0分」と「30分」にアクセスが急増する現象を指しています。Slackのウェブ層はこうしたミニピークに対応するため、「CPU使用率」と「Apacheのワーカースレッドの状況」をもとに自動スケーリングが設定されていますが、今回の障害ではネットワーク障害が同時発生していたため、自動スケーリングが予期せぬ動作を示したとSlackは説明しています。
当時の自動スケーリングの動作をタイムラインで表した図が以下。午前7時よりも前に発生していたネットワーク障害によりワーカースレッドが待機状態となったため、インスタンスのCPU使用率が低下。その情報に基づき、ウェブ層のスケールダウンが実行されています。しかし、ウェブ層とバックエンドとの通信にまでネットワーク障害が影響し始めると、待機状態のワーカースレッドが急増。それに伴って大幅なスケールアップが実行されました。午前7時1分から午前7時15分の間で、1200ものインスタンスがウェブ層で新規に起動されたとのこと。
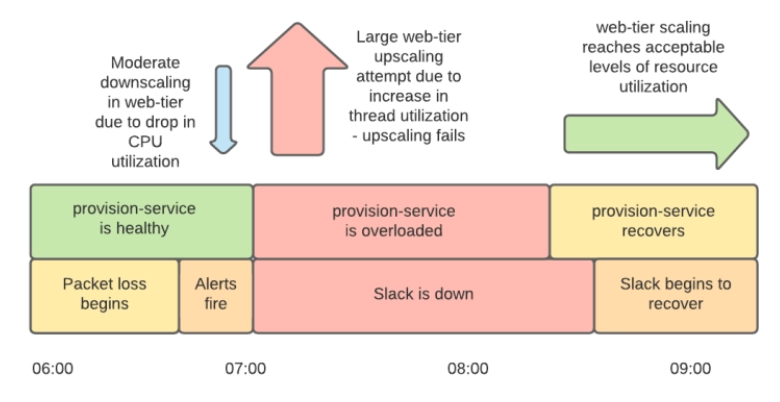
また、自動スケーリングを行うプロビジョニングサービスもネットワーク障害による通信遅延の影響を受けており、その状況下で多数のインスタンスを起動する処理を行ったことで、プロビジョニングサービスも「Linuxのファイルオープン数上限」と「AWSのクォータ」に達し、過負荷状態に陥っていました。そのため、プロビジョニングサービスはインスタンスの起動処理をウェブ層として利用できる状態まで実行できていなかったとのこと。また、そうした不完全なインスタンスが多数起動することでインスタンスの起動上限数に達してしまい、新しい監視ダッシュボード用のインスタンスすら起動できなくなってしまいました。
午前8時15分ごろ、インフラチームの手によりプロビジョニングサービスが回復し、ウェブ層はサービスを提供できる状態になりました。ロードバランス層では依然としてエラーが発生していましたが、多数のエラーが発生している場合にトラフィックを全インスタンスに均等に振り分ける「パニックモード」などを利用することで、Slackのサービスを回復できたとのこと。しかし、ネットワーク障害の影響により、Slackのサービスにはまだ遅延が生じている状態でした。
最終的に、AWSのエンジニアの調査により、ネットワーク障害はAWSが管理している「AWS Transit Gateway(TGW)」で発生していると判明。SlackではTGWを別々のアカウントに属するVPCのハブとして利用していましたが、このTGWが「年末年始休暇でトラフィックが少ない状態」から「仕事始めの急激なトラフィック増」に対応できていなかったとのこと。AWSがTGWを手動でスケーリングすることでネットワーク障害は解決し、Slackのサービスは平常運転に戻りました。
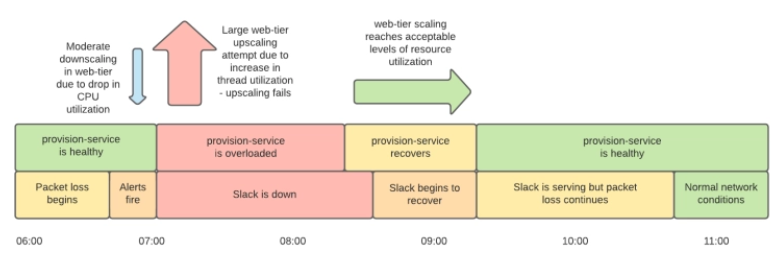
初期に発生した監視システムの異常についてもTGWが原因で、ダッシュボード用のインスタンスとバックエンドのデータベースが別々のVPCに配置されており、TGWを介した通信に依存していたためでした。今回の障害を受け、AWSはTGWのスケーリングアルゴリズムを見直すとSlackに報告。また、Slackは次の長期休暇時にTGWのスケーリングを事前に行ってもらうようリマインドを設定したほか、プロビジョニングサービスのロードテストや、死活監視および自動スケーリング設定の見直しを行うと報告しています。
・関連記事
Slackはスピードと信頼性を両立したソフトウェア開発をどのように実現しているのか? - GIGAZINE
Slackが約2兆8900億円でSalesforceに買収される - GIGAZINE
Slackが2020年5月に起こした大規模障害の原因は何だったのか? - GIGAZINE
Googleのサービスが45分間にわたり利用できなくなる大規模障害が発生、原因は認証サービスのストレージ問題 - GIGAZINE
iCloudで36時間にわたってアクセス障害が発生、「クリスマスプレゼント」が原因か - GIGAZINE
・関連コンテンツ