NVIDIAが高精度な画像生成AI「eDiffi」を発表、従来の「Stable diffusion」や「DALL・E2」よりテキストに忠実な画像生成が可能

大手半導体メーカーでありAI研究にも力を入れているNVIDIAが、新たな画像生成AIである「eDiffi」を発表しました。NVIDIAはeDiffiについて、世界中で話題となっている「Stable Diffusion」やOpenAIの「DALL・E2」といった従来の画像生成AIより入力テキストに忠実な画像を生成できると主張しています。
[2211.01324] eDiffi: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
https://arxiv.org/abs/2211.01324
eDiff-I: Text-to-Image Diffusion Models with Ensemble of Expert Denoisers
https://deepimagination.cc/eDiffi/
Nvidia's eDiffi is an impressive alternative to DALL-E 2 or Stable Diffusion
https://the-decoder.com/nvidias-ediffi-is-an-impressive-alternative-to-dall-e-or-stable-diffusion/
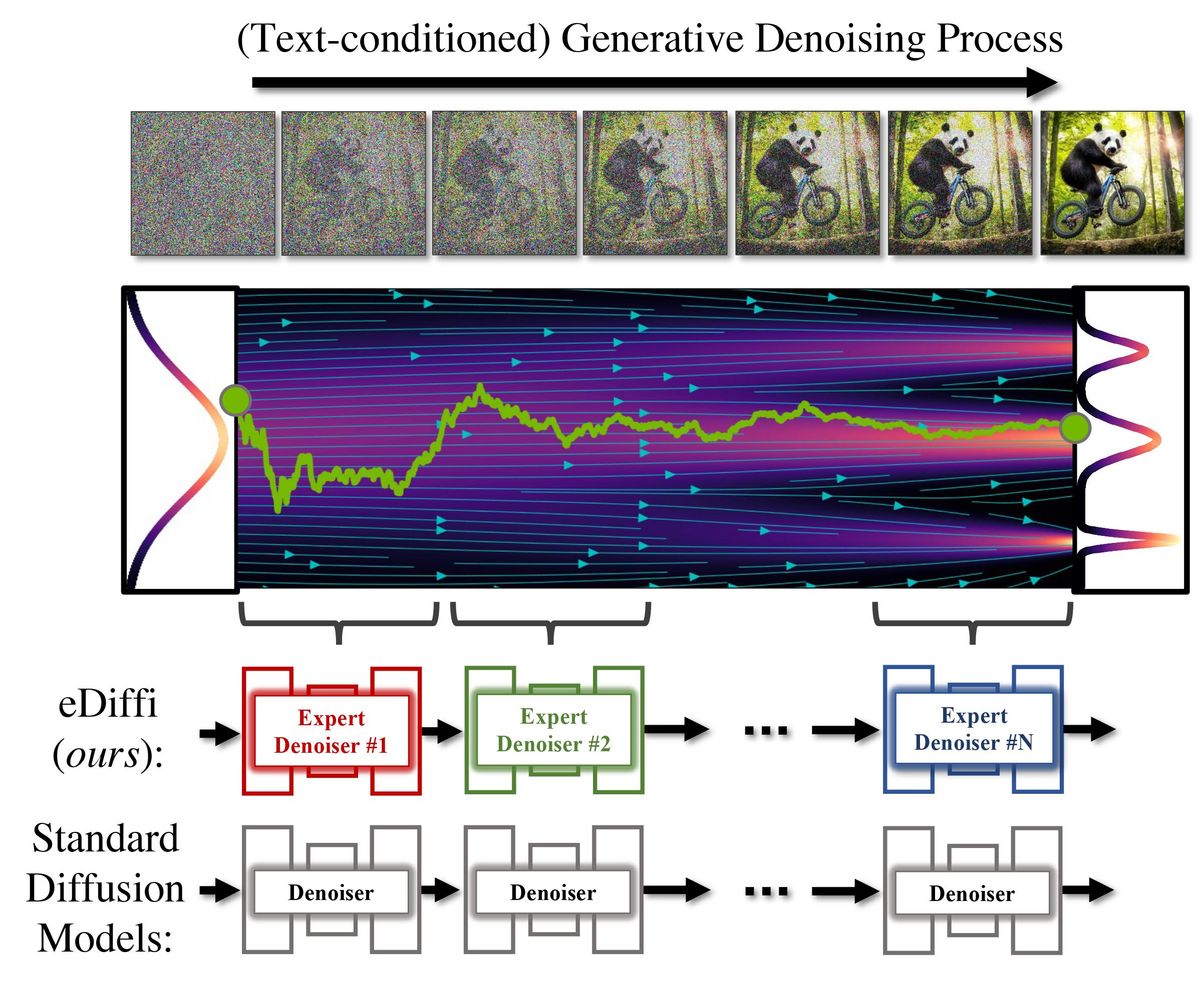
入力されたテキストを基に画像を生成するeDiffiでは、Stable DiffusionやDALL・E2でも使われている「拡散モデル」という画像生成プロセスを使用しています。拡散モデルは、ノイズだけの画像からノイズを除去するプロセスを反復し、最終的にきれいな画像を生成するという仕組みで画像を生成するものです。
従来の画像生成AIとeDiffiが異なる点は、通常の画像生成AIは単一のノイズ除去モデル(デノイザー)でトレーニングしている一方、eDiffiはノイズ除去の段階ごとに異なるデノイザーでトレーニングしているという点です。これにより、従来の画像生成AIよりも高精度な画像を生成できるとのこと。
eDiffiの画像生成がどれほど高精度なのかは、以下の動画を見るとわかります。
eDiffi: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers - YouTube
以下は左から「美しい木々が生い茂る神秘的な森の中にあるポータルを、非常に精細に描いたデジタルペイント。ポータルの前に人が立っている」「お化け屋敷で猫が魔法使いの帽子をかぶって魔女の格好をしている高精細のズームしたデジタルペイント。アートステーション(イラスト投稿サイト)」「美しい海の風景の画像。海の真ん中に大きな岩があり、背景には山がそびえ、太陽が沈んでいく」というテキストに基づいて、eDiffiが生成した画像です。どの画像もクオリティが高く、テキストの指示を忠実に反映しています。

また、テキストによる指示と簡単なペイントによる指示を組み合わせ、思い描いた通りの構図の画像を生成することもできます。
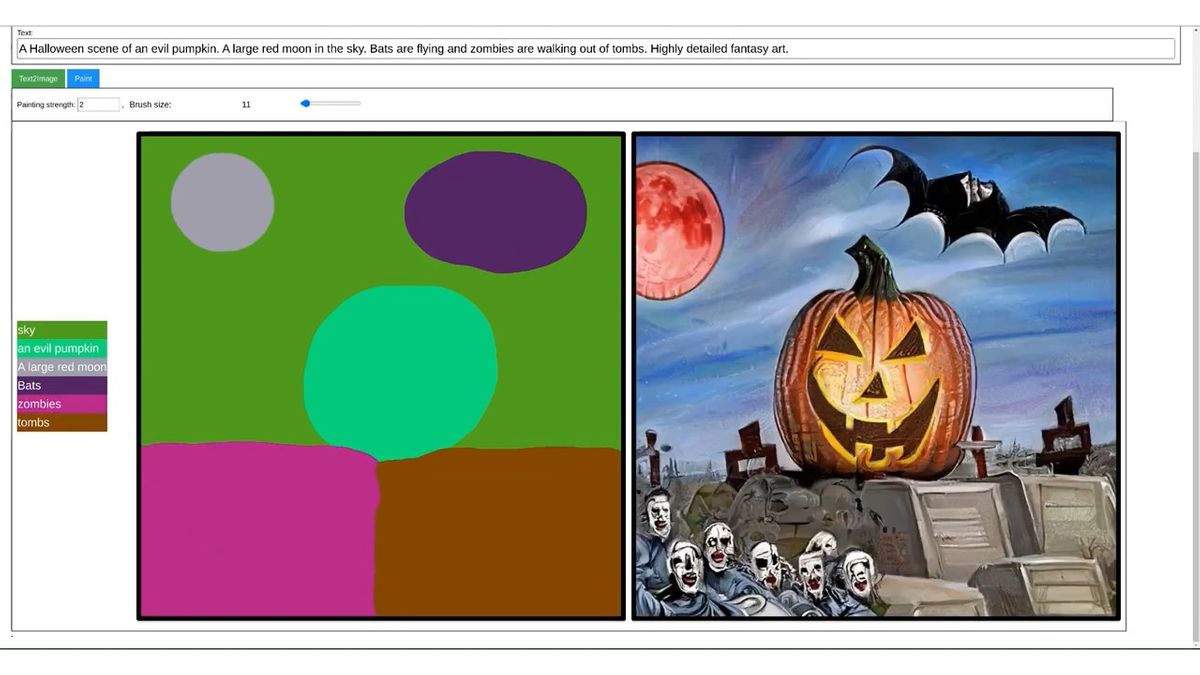
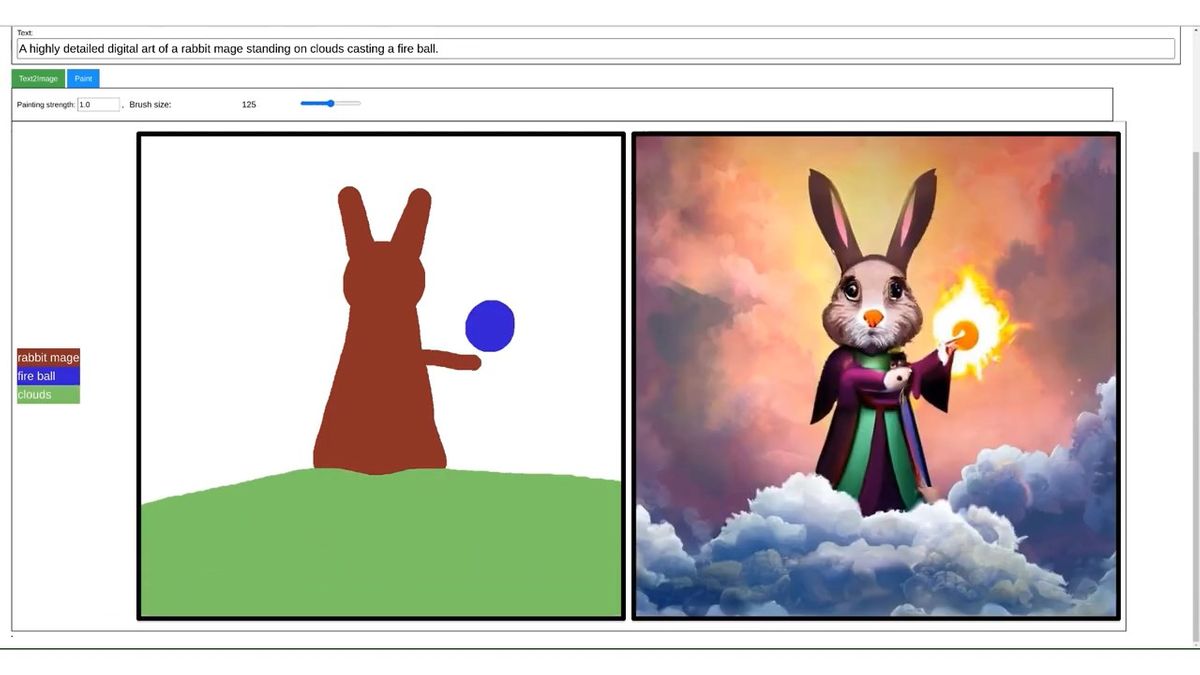
テキストとは別に「画風の参考にする画像」を指定することで、好きな画風で画像生成することも可能です。


eDiffiは既存の画像生成AIと比較して、よりテキストの指示に忠実な画像を生成できるとのこと。以下は、「緑のシャツを着たゴールデンレトリバーの子犬の写真。シャツには『NVIDIA rocks』というテキストが書かれている。背景はオフィス。4K、デジタル一眼レフカメラ」というテキストを基に、左からStable Diffusion、DALL・E2、eDiffiが生成した画像を並べたもの。いずれもゴールデンレトリバーの子犬が緑のシャツを着ているところまでは再現できていますが、「NVIDIA rocks」という文字が正確に書かれているのはeDiffiのみです。

「テーブルの上に2つの中国のティーポットがある。片方のポットには龍の絵が、もう片方のポットにはパンダの絵が描かれている」というテキストで生成した画像は以下の通り。この場合も、パンダの絵が認識できるのはeDiffiだけとなっています。

「青いシャツを着た犬と赤いシャツを着た猫が公園に座っている写真、フォトリアリスティック、一眼レフカメラ」というテキストで試したところ、eDiffiだけが青いシャツを着た犬を再現することができたそうです。

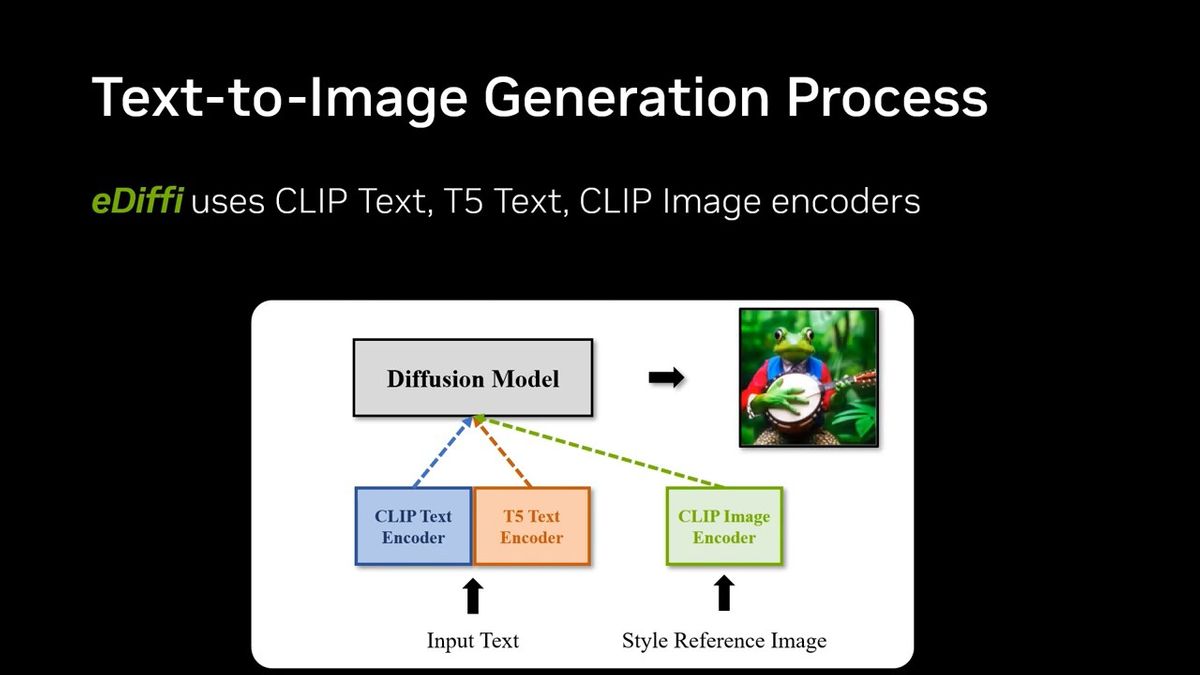
eDiffiでは、Googleの自然言語処理モデルである「T5(Text-to-Text Transfer Transformer)」と画像分類モデルの「CLIP」を組み合わせており、画像スタイルを模倣する際にはオプションとしてCLIP画像エンコーダーを使用するとのこと。T5のみを使用すると正しくないオブジェクトが含まれる場合があり、CLIPのみだと細部が欠落する場合があるそうですが、両者を併用することで最高のパフォーマンスが得られることがわかったとNVIDIAは解説しています。
・関連記事
画像生成AI「Stable Diffusion」にたった数枚のイラストから絵柄や画風を追加学習できる「Dream Booth」が簡単に使える「Dreambooth Gui」レビュー - GIGAZINE
無料で画像生成AI「Stable Diffusion」をWindowsに簡単インストールできる「NMKD Stable Diffusion GUI」の使い方まとめ、呪文の設定や画像生成のコツがすぐわかる - GIGAZINE
Microsoftが画像生成AI「DALL-E 2」を新アプリのMicrosoft Designerや検索エンジンのBingに統合すると発表 - GIGAZINE
「画像が他の画像へ変化するまでの過程」を画像生成AI「Stable Diffusion」で生成できるスクリプト「Interpolate」の導入手順&使い方まとめ - GIGAZINE
画像生成AIを「DALL・E」アプリに組み込めるAPI「DALL・E API」のパブリックベータ版が公開される - GIGAZINE
NVIDIAが超高性能ディープフェイク生成AI「Implicit Warping」をひっそり開発している - GIGAZINE
・関連コンテンツ